Decision Tree: How do I set the Algorithm Options?
The Algorithm Options determine how splits are generated at each stage in the Decision Tree. The Next Splits panel provides information on how the Algorithm Options have been applied to create each split.
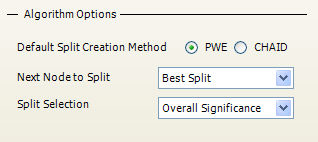
To update the Algorithm Options, select the Basic Options tab from the Build Options menu.
Each step in building a tree is broken down in to 3 stages:
-
Choosing which node(s) to split.
-
Creating a set of candidate splits for this node.
-
Deciding which of the candidate splits to use.
1. Choosing which node to split
Only leaf nodes can be split provided that they have not failed any of the Stopping Conditions. See How do I set the Stopping Conditions?.
Which of these nodes is chosen depends on the "Next Node to Split" option.
|
Next Node to Split |
Description |
|
Best Split |
This is the default option. This chooses the node which offers the best split. This ensures that the optimal next step is always taken. |
|
All Leaves |
This grows all the leaf nodes in one step. This provides a very fast way to grow a tree, although it is harder to review each step. System memory constraints could impact on the number of nodes that can be split, especially if working with a large database or variables of high cardinality. For more information see How do I change the default Options? |
|
Largest |
This will choose the leaf node with the largest number of base records. This has the effect of exploring all areas of the tree, since the largest node could be anywhere in the tree. |
|
Average Gain |
This chooses the node with the analysis % most similar to the root node. This has the effect of exploring the nodes which are neither good nor bad. These are often the nodes which can be split effectively to find people in the analysis selection. |
|
Highest Gain |
This chooses the node with the highest gain compared to the root node (i.e. the highest analysis %). This has the effect of focusing on one area of the tree, homing in on better and better nodes and creating smaller and smaller nodes. |
|
Lowest Gain |
This chooses the node with the lowest gain compared to the root node (i.e. the lowest analysis %). This has the effect of focusing on one area of the tree, homing in on the poorest nodes. This could be useful, if your objective is to avoid people in the analysis selection (e.g. insurance risks) |
2. Creating a set of candidate splits
Within the node chosen for splitting, splits are created for all dimensions that have been set to "Create Split" on the dimensions tab.
There are 2 main methods for creating splits: PWE and CHAID. These are explained in more detail in the following sections: How do I set the PWE Options? andHow do I set the CHAID Options?
All new splits will be created according to the "Default Split Creation Method".
Having created splits automatically in this way, the user can modify them extensively. See How do I manually control the build process? section for more details.
3. Deciding which of the candidate splits to use
All splits are assessed against the Split Validation Conditions and are marked invalid accordingly.
For a split to be chosen by the automatic build process it must be both valid and have been set to "Use Split" on the dimensions tab.
The split chosen will always be the top ranking split (rank 1). Different measures can be used to rank the splits, as determined by the Split Selection.
|
Split Selection |
Description |
|
Best Variable |
This option assesses each dimension before splits are created. The "Cramer's V (before split) statistic is used to rank the splits.
This identifies the dimension whose categories show the biggest differences with respect to the analysis selection.
Since this is the value based on the categories this does not guarantee that the splits themselves are the best. |
|
Best Node |
This option assess the dimensions once the splits are created and compares the least distinct node from each split, i.e. the child node which is most similar to the parent node ( has the lowest Z Score).
The split chosen is the one whose least distinct child node is the best.
This option effectively ensures that the minimum level of significance amongst the child nodes is as high as possible. This approach works well for Binary splits, but not so well for multiple splits. It is perfectly acceptable to create a 3-way split, for example, where one node has a higher analysis % another has a lower analysis %, but the third is average and so not distinct from the parent. |
|
Overall Significance |
This option assess the dimensions once the splits are created and uses a measure that assesses the split as a whole, rather than just looking at a single node from each split.
The measure used is based on the Chi Square test
of association between the child nodes and the analysis selection. The
Significance measure quoted in the Next Splits panel is |
See Statistical Terminology for more details on the statistics.